This post is about a combination of best practices combined together. The best practices are the UI-Manager pattern (The UIManager Pattern | The Groundside Blog by Duncan Mills), using JavaScript in a fragment (Gotcha when using JavaScript in ADF Regions | Oracle OTN Harvest: Oracle ADF and MAF Blog) and running a JavaScript function when the fragment is loaded the first time (Lazy Initalizing Beans).
Use Case
We create a digital clock in a fragment. This sounds simple, but there are a couple of things to think about.
- How to set up a digital clock in JavaScript
- A fragment is not a document, so we can’t use the af:document to load JavaScript in a fragment
- Calling a JavaScript method on the inital load of the fragment from a bean
- A fragment is a task flow built from .jsff files which are ui:components in 12.2.1.4
- A fragment can be used multiple times on one or more pages. It should be a boundary of work. There should be no link to the outside but parameters passed to the task flow.
Implementation
We combine the best practices mentioned in the intro to implement the use case.
Digital Clock
The first part is simple. To implement a digital clock we can use JavaScript. The JavaScript handles the update of the time in the fragment. We can search the WWW for a peace of JavaScript. I end up with the two function below:
function startTime() {
var today = new Date();
var h = today.getHours();
var m = today.getMinutes();
var s = today.getSeconds();
m = checkTime(m);
s = checkTime(s);
document.getElementById('txt').innerHTML = h + ":" + m + ":" + s;
t = setTimeout('startTime()', 500);
}
function checkTime(i) {
if (i < 10) {
i = "0" + i;
}
return i;
}Looking at the code should ring some bells. This code should no used as is in any ADF application as it has some problems (if it runs in the first place).
Making the JavaScript usable in a fragment
The function startTime() uses document.getElementById(…) to find a specific element on the page by it’s ID. This might work on a single page but is problematic in ADF where naming containers (like table or regions) will change the ID of the elements inside the container. This is needed as a region (a task flow build from fragments) can be used multiple times on one page. If an element in the region would have the same ID every time you would not know which to address. This is the reason the naming container changes the ID of the elements inside.
Now that we know that the ID will change we change the JavaScript to an ADF digestible format
function startTime(id) {
//console.log('ID=' + id);
var today = new Date();
var h = today.getHours();
var m = today.getMinutes();
var s = today.getSeconds();
m = checkTime(m);
s = checkTime(s);
var text = AdfPage.PAGE.findComponentByAbsoluteId(id);
var time = h + ":" + m + ":" + s;
text.setValue(time);
t = setTimeout(startTime, 500, id);
}
function checkTime(i) {
if (i < 10) {
i = "0" + i;
}
return i;
}First, note that the function startTime(…) has got an ID as a parameter. This ID is the clientID of the component that we use to show the time. The method to locate the right component uses this clientID too. Finally, the setTimeout(…) function had to be changed to pass the clientID as a parameter.
With these changes, an ADF RichOutputText component with the given clientID gets updated every 500ms.
Loading JavaScript in a fragment
The next part is how to load the JavaScript as part of a fragment. This is described in https://blogs.oracle.com/jdevotnharvest/gotcha-when-using-javascript-in-adf-regions by Frank Nimphius. The short blog tells us to use an af:panelFormLayout and inside this component to add the af:resource to load the JavaScript.

The af:panelFormLayout doesn’t need any other component, its just used as trigger to load the script. Instead of adding the JavaScript directly into the resource tag, we can load a JavaScript file.
Calling a JavaScript function on the initial load of the fragment
The final task is to call the startTime(…) method on the initial load of the fragment providing the right clientID for the af:outputText that shows the time.
I mentioned before, that a fragment doesn’t have an af:document tag (and can’t have one!). This is a problem as there is no ‘onLoad’ JavaScript event available for fragments. Depending on the use case you can use the default action of the task flow and inject the needed JavaScript call from there. However, in our use case, this isn’t possible as we need the af:outputText to be available. This is only the case when the fragment renders and not when the default method is called before the fragment is rendered.
Here Lazy Initalizing Beans comes to help. We need the clientID of the af:outputText to pass it to the startTime(…) method. We use The UIManager Pattern | The Groundside Blog by Duncan Mills best practice to get the clientID.

We bind the af:outputText component to a bean in backingBeanScope (REMEMBER: don’t bind components to a bean in scope higher than request!) to get the clientID inside the naming container on the page. Make sure that the clientComponent property is set to true as you don’T get the clientID otherwise!
The next thing to do is to use the lazy init technique to inject a JavaScript call to startTimer(…) passing the clientID of the bound component. As this should only be done once, we need to set a flag that we can use to know if the initialization has already be done. The bean in backingBeanScope doesn’T live long enough for this. We need a bean in pageFlowScope. In the task flow, we define a bean with the name DigitalClockContext (DigitalClockContextBean.java) in pageFlowScope. This bean holds the status information for the region defined by the task flow. In our case a flag that shows us that the timer in the region has been started by injecting a JavaScript call to startTimer(…) method.

The DigitalClockContextBean.java looks like

It is just holding the flag initTime. The second part of the lazy init is done, when the value property of the af:outputText is read from the DigitalClockBean in backingBeanScope. We set the value property to an EL that points to the getTime() method in the DigitalClockBean

In the bean, the method checks the status of the flag from the DigitalClockContext and if not already initialized injects a JavaScript method call to startTimer(…) with the clientID from the af:outputText that is bound to the same DigitalClockBean.
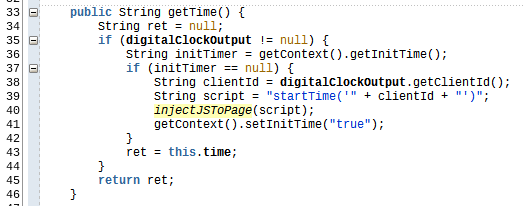
In the getTime() method we first check if the bounded component is already set (line 35), then we get the flag from the DigitalClockContextBean, check if the flag is null. In this case, we get the clientID from the bounded component and inject the JavaScript function call to the startTimer(…) method with the clienID.
One other point is how to get the DigitalClockContextBean inside the DigitalClockBean. For this we use a managed property

This makes the DigitalClockContextBean available in the DigitalClockBean. All we need to do is to add a getter for the DigitalClockContextBean and a variable to store the value

Now we can test the task flow by adding it multiple times to a page (line 17 and 19)
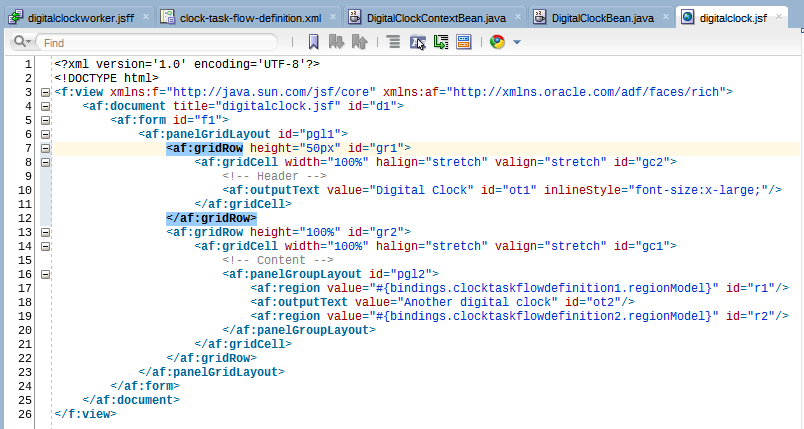
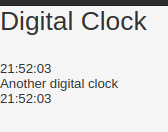
This will get us this output
You can download the sample application from GitHub. It was created using JDeveloper 12.2.1.4 and don’t use a DB.