
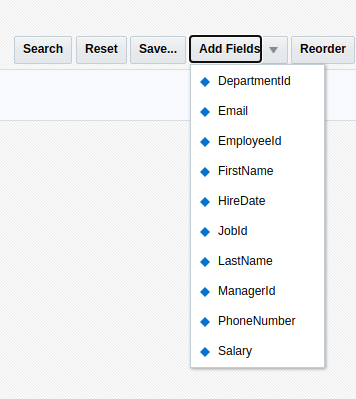
A couple of weeks ago a question in the Oracle ADF Community asked for help with af:query in advanced mode. In detail, the user wanted to know how to hide some fields from the ‘Add Fields’ LOV available in the advanced mode of the af:query component.

You can hide fields declaratively in the view criteria the af:query. For this, you uncheck the queryable checkbox for the attribute. If you do this for e.g. the CommissionPct attribute

You don’t get this field when you click on the add button
But you don’t see the field also.

A field that is hidden this way cant be used in the query.
Use Case
The use case is to hide the field only from the list of fields to add. This is useful if you only want the field in the query once.
Solution
A look at the documentation reveals that there isn’t any property to do this, I didn’t find one at least.
The solution that I’m showing here is to use CSS to hide the field from the list that is built by the af:query component when you click the add fields button.
How to find what to hide?
Well, before we can hide something with CSS, we need to find out what to hide. First thing to try is to use a skin selector. However, when I looked into this, I did not find any skin selector that could be used for this. All selectors available for the af:query component are used for different things.
Before we start looking into skin and or CSS, we disable content compression to see the real selector names by setting a context parameter in the web.xml file

When we run the application after that, we can use any browsers development tools and look at the generated HTML code (here I use Chrome):

The blue marked part shows the markup for the ‘Email’ in the popup of the ‘Add fields’ button. The task is to hide this EMail from the add Fields list but to let it be available in the list of fields on the left.
Now that we found the right element, we can hide it simply by setting the CSS
display : none;
to it.
Well, it’s easy to do in the browser development tools, but how to do it in the application?One way would be to create a skin selector for the class
‘af_commandMenuItem af_commandMenuItem-menu-item’
but this would change all components using this skin.
My solution is to add the CSS directly to the JSF page using an af:resource tag like

The trick is to use CSS to address the right element. You can look up all available selectors e.g. at w3schools.com.
We are looking for a tr element that has a specific id and can use the selector shown in line 6 in the image above.
Running the application with this CSS added to the page results in

The Email field is still present once, but it can’T be added again as it is not visible in the list of fields to add.
The one disadvantage using this technique is that we have to specify the element by its name. This is not dynamic but a fixed value. Ich you add another query to the page you gen another id and you have to change the CSS.
In the end, it’s your decision if you use this technique, but I guess it is a valid one for this special use case.
You can download the sample application from GitHub. The application was built using JDeveloper 12.2.1.4 and uses the HR DB.






















































































